
Amazon Redshift
Learn how to set up a Amazon Redshift source connection
Requirements for Connection
- Access to an AWS account and Amazon Redshift cluster
- The user has an admin role to access the Amazon Redshift cluster. This user must also have created schema privileges.
- Add the IP of GrowthLoop’s NAT in your Amazon Redshift Security Groups so that the web app can reach your Amazon Redshift instances. Reach out to [email protected] for the IP address.
- The Amazon Redshift cluster must be spun up and connected to a database. Click Connect to the database. If a database is not connected to Amazon Redshift, the status will be blank and you need to click Change connection to connect to your database.
If the database is connected to Amazon Redshift, you will see the status Connected.
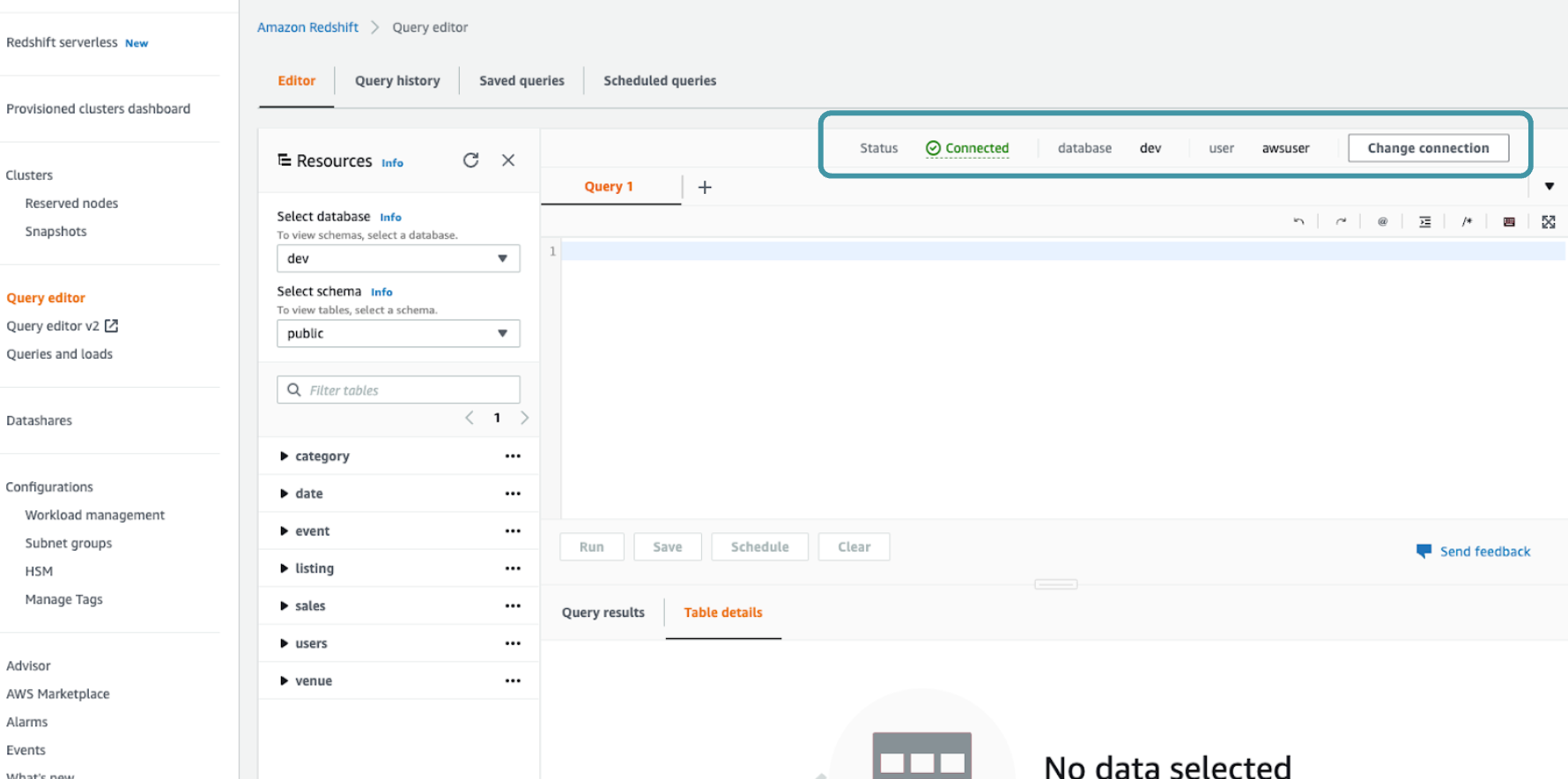
- Create schema flywheel_system in the Amazon Redshift cluster’s database. In the query editor, paste and run this command:
create schema flywheel_system - If you will be using Signal Routing, run this command in the Amazon Redshift cluster’s query editor:
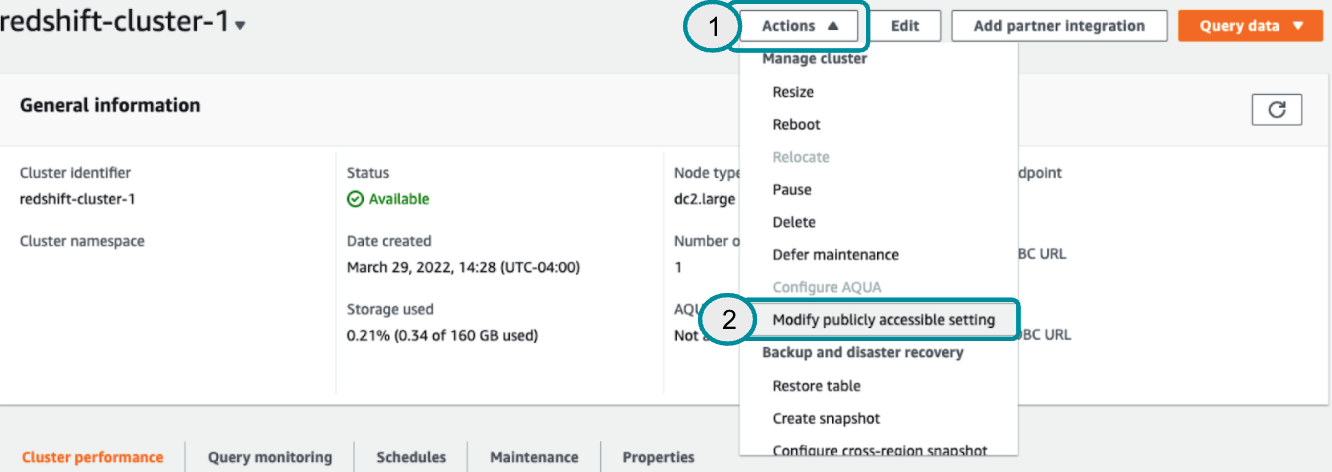
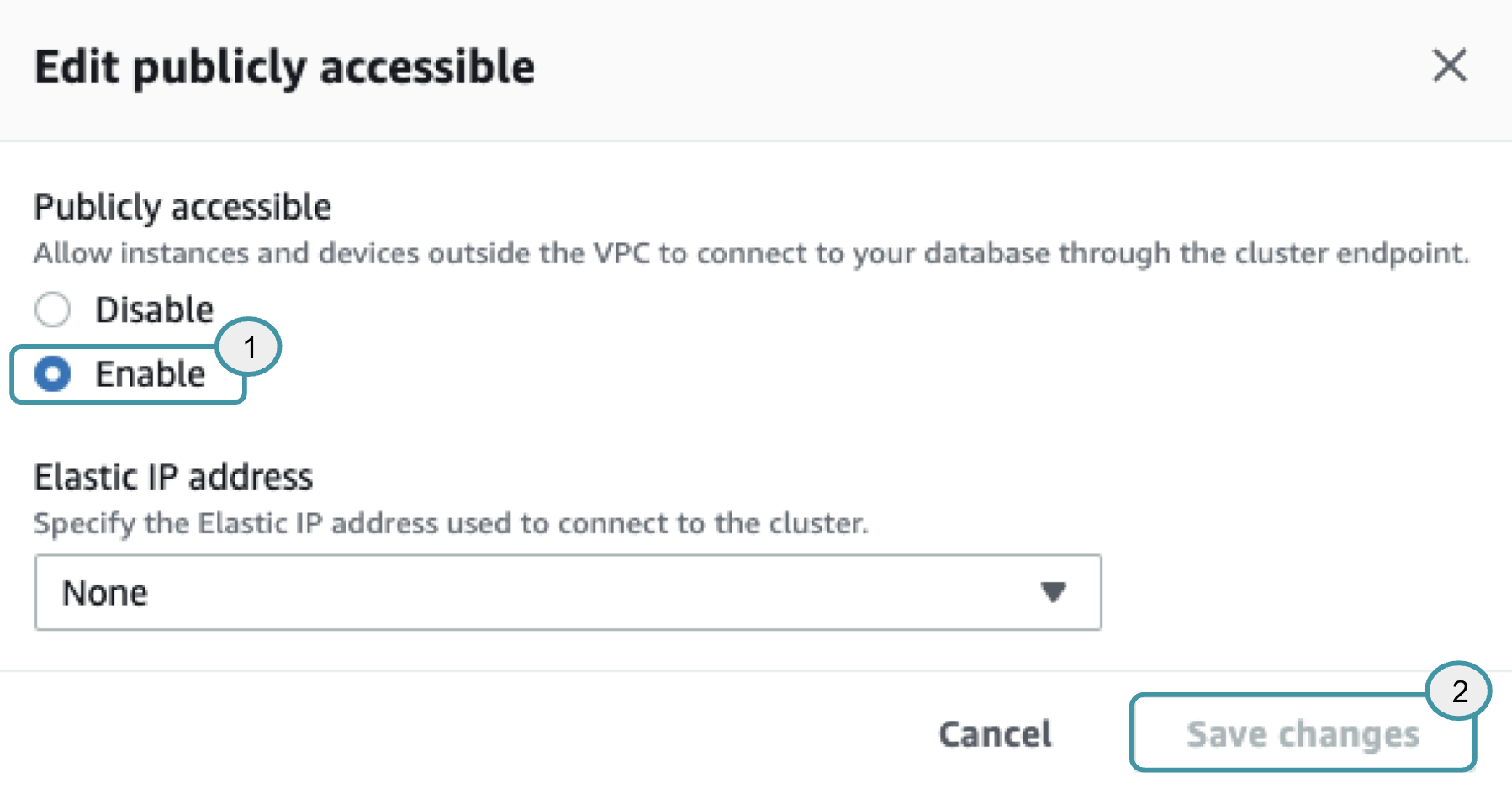
create schema signal_snapshotsSee<link>for more information on signal routing with GrowthLoop. - Amazon Redshift clusters must be publicly accessible. You can make that change in the Amazon Redshift UI. Select the cluster, click Actions, and Modify publicly accessible setting. Select Enable in the popup and Save changes.
How To Connect in the App
- Visit the GrowthLoop application. If you were provided with a different application URL, use that.
- Sign up using your company credentials.
- If necessary, verify your email by clicking the verify link in the email sent to your email address.
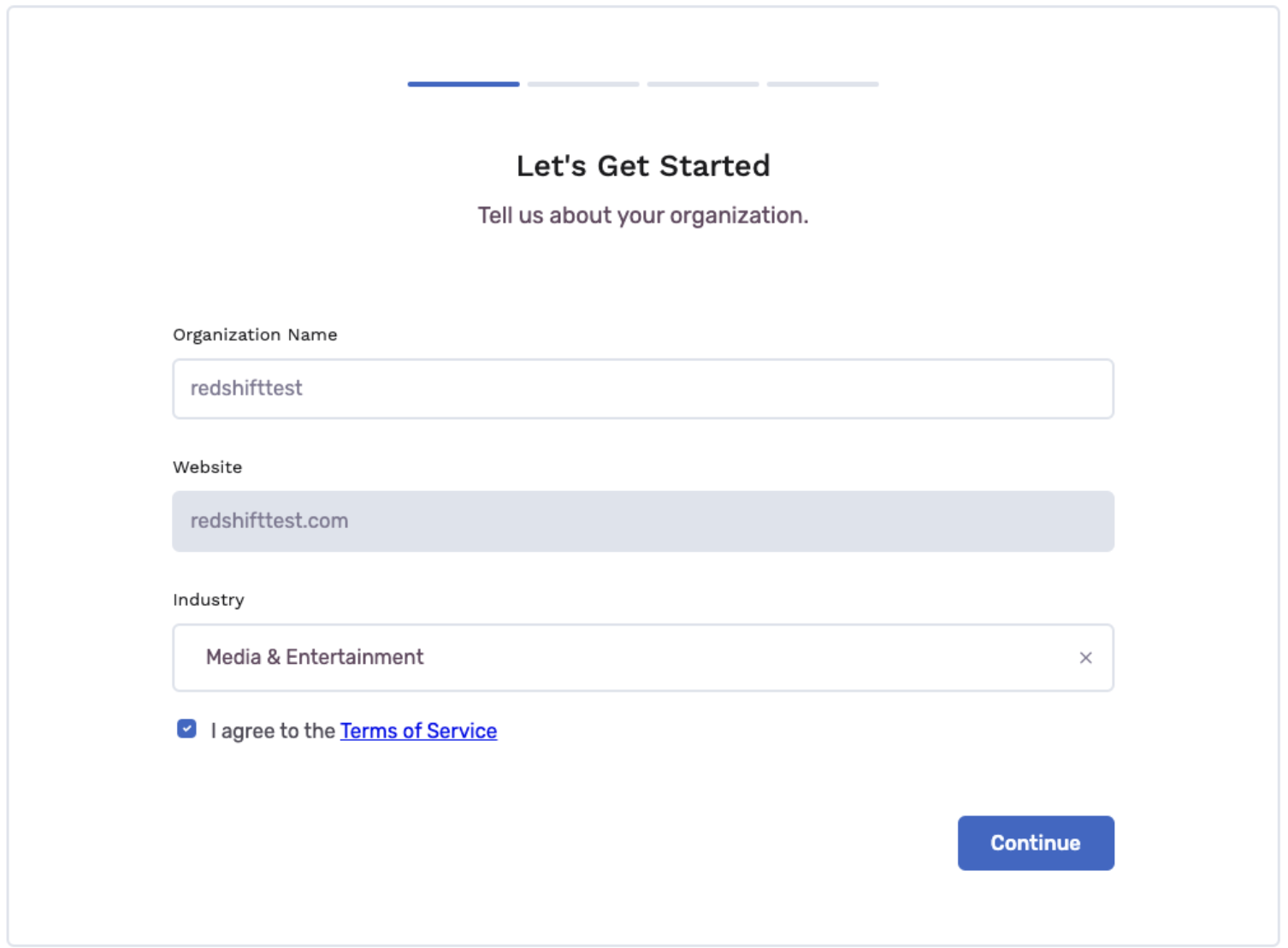
- Return to the application and enter your Organization name and Industry. Click the checkbox to agree to the terms and then Continue.
- Select Amazon Redshift as the data warehouse you wish to connect to.
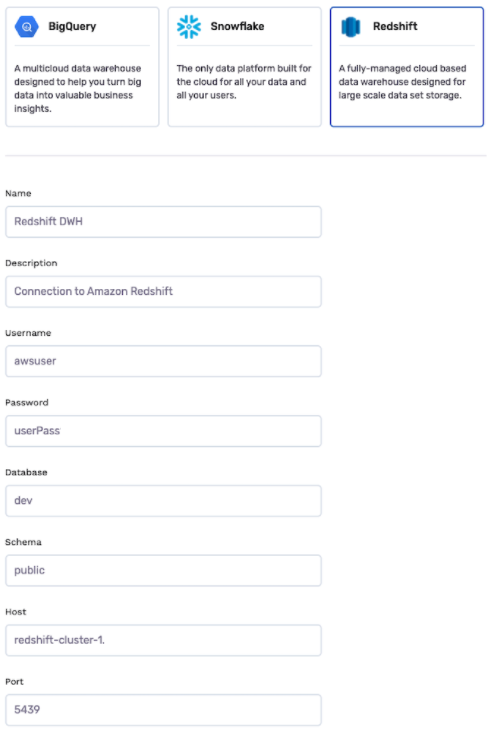
- Next, enter the required information to connect to Amazon Redshift:
- Name: name the connection to your data warehouse. This is somewhat arbitrary.
- Description: description of the connection to your data warehouse. This is somewhat arbitrary.
- Amazon Redshift username: username for the user that allows access to the Amazon Redshift cluster where your data is stored. This can be found on the Amazon Redshift cluster UI’s Properties tab, or in the Query Editor when it is connected to your database.
- Amazon Redshift password: admin user password for the user that allows access to the Amazon Redshift cluster where your data is stored. You can change the admin user password in the Amazon Redshift cluster UI’s Properties tab if necessary
- Database: name of the database that you want to connect to the app.
- Schema: name of schema for the table you want to connect to the app. For example, If you are looking to connect your user table to the app, select the user schema.
- Host: Database endpoint, without the port and database name.
- Copy the cluster endpoint. It should look have this format: <host>:<port>/<database>
- Remove the port and database name, leaving just the host
- Example: r edshift-cluster-testname0123.us-east-1.redshift.amazonaws.com
- Enter the edited host as the host in the app
- Port: Open the port to access the database. The port can be found in the Amazon Redshift cluster UI’s Properties tab, or as part of the database endpoint. The format of the endpoint is <host>:<port>/<database>
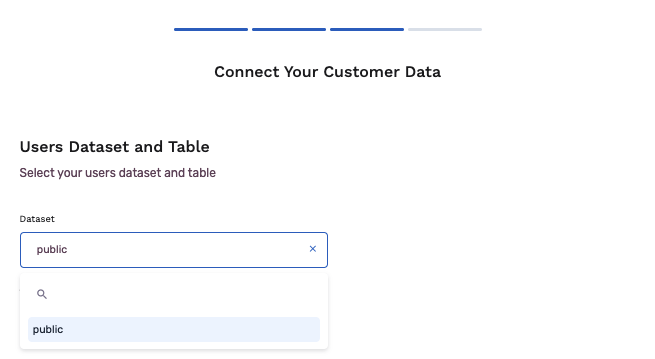
- Select the dataset you wish to connect to the app.
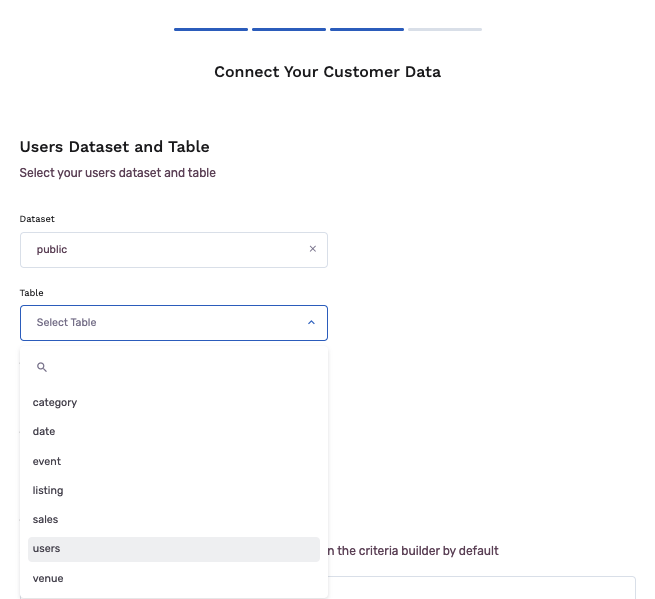
- Select a table you want to connect to. You can add more tables later, as well.
- Add table alias and description
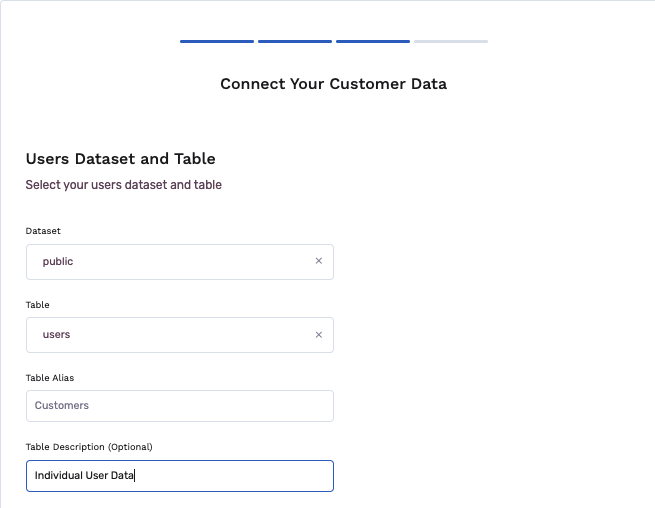
- Select the unique key, which uniquely identifies a database record.
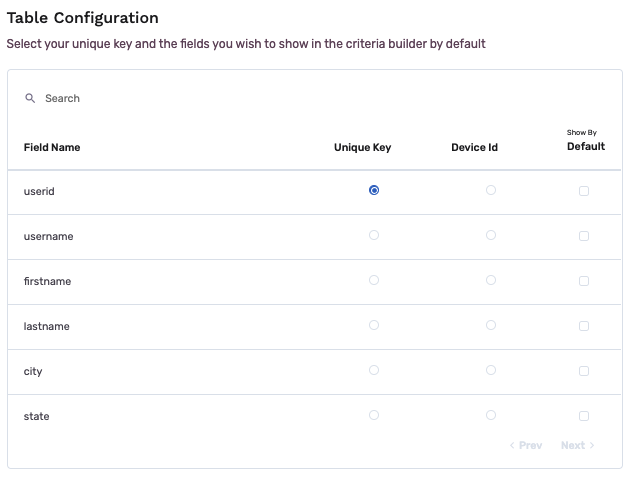
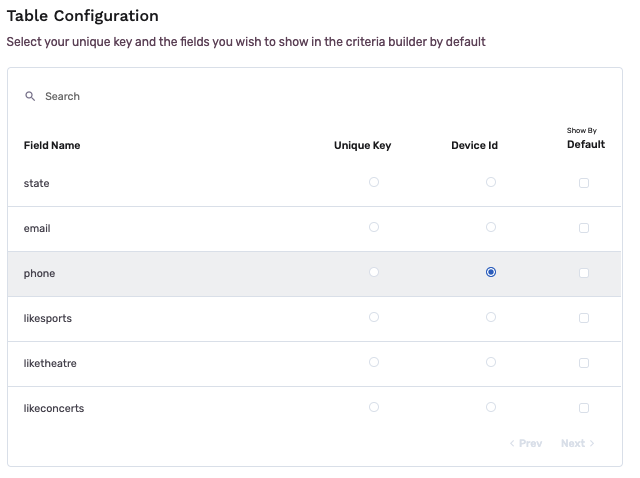
- If required, select a device ID. The device ID is often used to target an individual during a marketing campaign, so it will be necessary to define the device ID before sending any data to a marketing destination.
- Select fields that you would like to see by default in the app when you create a new audience. Additional fields will be available in the app to manually add to an audience. Default settings can be edited at any time in the app.
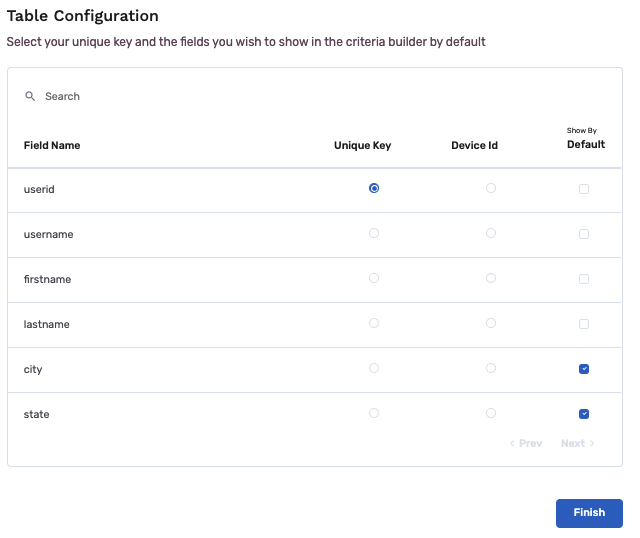
- You have successfully connected your Amazon Redshift database to the app!
AWS recommends that customers create separate queues for monitoring database queries. Instructions for setting up these queries can be found at this link.
Updated 4 months ago
Did this page help you?